Trong bài viết chúng ta thảo luận về việc phân tích volume. Phân tích volume cần việc xem xét các cấu trúc dữ liệu mà liên quan tới việc phân vùng (partitioning) và lắp ghép (assembling) các bytes trong các thiết bị lưu trữ do vậy chúng ta có được các volumes. Các volumes được sử dụng để lưu file system hoặc cấu trúc dữ liệu khác. Trong phần này chúng ta tiếp cận các khái niệm của phân tích volume và thảo luận các nguyên lý mà áp dụng cho tất cả các kiểu hệ thống volume. Trong các bài tiếp theo chúng ta thảo luận về các kiểu phân vùng và lắp ghép các hệ thống
Giới thiệu
Phương tiện lưu trữ kĩ thuật số được tổ chức để cho phép việc lấy dữ liệu được hiệu quả. Trải nghiệm phổ biến nhất với một volume là khi chúng ta cài đặt Microsoft Windows và tạo các phân vùng (partitions) trên đĩa cứng. Quá trình cài đặt là quá trình tạo các phân vùng chính và phân vùng logic, và cuối cùng trong các bước cài đặt máy tính liệt kê một danh sách các "drives" hoặc "volumes" để lưu trữ dữ liệu. Một quá trình tương tự xảy ra khi cài đặt một hệ điều hành UNIX, và nó trở nên phổ biến trong các môi trường lưu trữ rộng lớn để sử dụng các phần mềm quản lý volume để có nhiều đĩa xuất hiện như là chúng bao gồm một đĩa lớn.
Trong suốt quá trình điều tra số, thông thường thì ta thu được ảnh của toàn bộ đĩa (disk image) và import image này vào các công cụ phân tích. Nhiều công cụ điều tra số tự động cắt (break) disk image ra thành các partitions, nhưng thỉnh thoảng chúng cũng gặp phải những vấn đề. Các khái niệm trong bài dịch này sẽ giúp một người điều tra hiểu các chi tiết về một công cụ đang làm điều gì và tại sao nó gặp phải các vấn đề nếu một đĩa bị lỗi. Ví dụ, khi các partitions trên đĩa bị xóa hoặc bị xóa đổi do nghi ngờ hay là một công cụ đơn giản không thể xác định vị trí một partition. Các thủ tục trong bài này cũng có thể hữu dụng khi phân tích các sectors mà không được cấp phát tới một partition.
Background
Các khái niệm Volume
Các hệ thống volume có 2 khái niệm trung tâm. Một là để lắp ghép (assemble) nhiều volumes lưu trữ thành một volume lưu trữ và khái niệm còn lại đó là để phân vùng (partition) các volumes lưu trữ vào trong các partitions độc lập với nhau. Thuật ngữ "partition" và "volume" thường được sử dụng thường xuyên cùng nhau, nhưng tôi sẽ đưa ra một sự khác biệt giữa chúng.
Một volume là một tập hợp các sectors có thể đánh địa chỉ mà một hệ điều hành (OS) hoặc một ứng dụng có thể sử dụng để lưu trữ dữ liệu. Các sectors trong một volume không cần phải là các sectors liên tiếp trên thiết bị lưu trữ vật lý; thay vào đó, chúng chỉ cần gửi đi một dấu ấn (impression) để cho thấy rằng chúng là gì. Một volume cũng có thể là kết quả của việc lắp ghép và sáp nhập các volumes nhỏ hơn.
Lý thuyết chung của các partitions
Một trong các khái niệm trong hệ thống volume là tạo ra các partitions. Một partition là một tập hợp các sectors liên tục trong một volume. Rõ ràng theo định nghĩa thì một partition cũng là một volume, là một khái niệm con trong khái niệm của volume, điều đó là lý do tại sao chúng ta hay bị nhầm lẫn. Tôi sẽ đề cập tới volume như là một partition được xác định vị trí như là một volume cha của partition. Các partitions được sử dụng trong nhiều hoàn cảnh, bao gồm
- Một vài file systems có một kích thước tối đa nhỏ hơn so với các đĩa cứng
- Nhiều laptops sử dụng một partition đặc biệt để lưu nội dung bộ nhớ khi hệ thống đi vào trạng thái sleep.
- Các hệ thống UNIX sử dụng các partitions khác nhau cho các thư mục khác nhau để giảm thiểu tối đa tác động cuả việc hư hỏng file system
- Các hệ thống dựa trên IA32 mà có nhiều hệ điều hành, ví dụ như Microsoft Windows và Linux, có thể yêu cầu các partitions khác nhau cho mỗi hệ điều hành
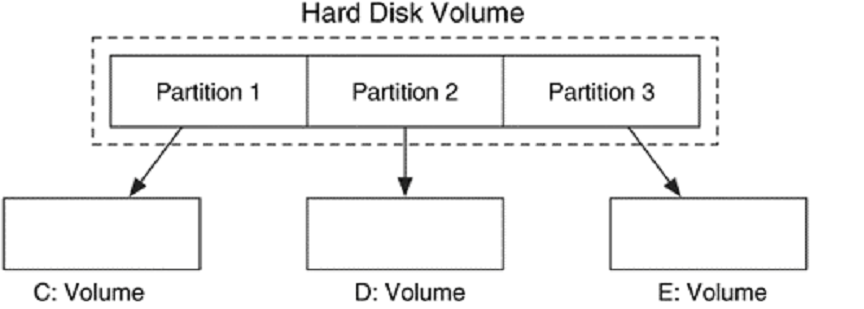
Hình 1. Một volume đĩa cứng được tổ chức thành 3 partitons và mỗi partitions được gán các tên volumes
Mỗi hệ điều hành và nền tảng phần cứng thì sử dụng một phương thức phân vùng khác nhau. Các hệ thống phân vùng phổ biến các một hay nhiều bảng, và mỗi entry của bảng mô tả một partition. Dữ liệu trong entry sẽ có sector bắt đầu của partition. Hình 2 cho ta một bảng mẫu với 3 partitions
Hình 2. Một bảng cơ bản với các entries cho start, end và type của mỗi partition
Mục đích của một hệ thống phân vùng là để tổ chức layout của một volume; do đó, chỉ dữ liệu cần thiết là vị trí bắt đầu và kết thúc cho mỗi partition. Một hệ thống partition không thể phục vụ mục đích của nó nếu các giá trị này bị lỗi hoặc là không tồn tại. Tất cả các trường khác, ví dụ như trường type và description, là các trường không cần thiết và có thể sai.Trong hầu hết các trường hợp, sector đầu tiên và cuối cùng của một partition không chứa bất cứ thứ gì nhận dạng chúng là các sectors rìa. Khi các cấu trúc hệ thống partition đang bị mất, các ranh giới partition có thể đoán được sử dung hiểu biết về những gì được lưu bên trong partition.
Chú ý rằng một hệ thống partition phụ thuộc vào hệ điều hành và không phụ thuộc vào kiểu interface trên đĩa cứng. Do đó, một hệ thống Windows sử dụng cùng một hệ thống partition không quan tâm về đĩa sử dụng AT Attachment interface (ATA/IDE) hay là một Small Computer Systems Interface (SCSI)
Việc sử dụng các Volumes trong UNIX
Các hệ thống UNIX thường không sử dụng các volumes theo cách mà hệ điều hành Microsoft Windows làm. Phần này dành cho những users không quen thuộc với UNIX, và nó cung cấp một overview về cách các volumes được sử dụng trong UNIX.
Trong UNIX, user không thấy được một vài "drives", ví dụ như C: và D:. Thay vào đó, user được thấy một chuỗi các thư mục mà bắt đầu bằng thư mục root, hoặc /. Các thu mục con của / hoặc là các thư mục con trong cùng một file system, hoặc chúng là các mouting points cho các file systems mới và các volumes mới . Ví dụ, một CD-ROM có thể được biểu diễn là E: drive trong Windows, nhưng nó có thể được mount tại /mnt/cdrom trong Linux. Điều này cho phép user thay đổi các drives thông qua việc thay đôỉ các thư mục, và trong nhiều trường hợp user không biết những gì chúng làm. Hình 3 cho ta thấy cách đĩa cứng và CD volumes được truy cập trong Windows và UNIX

Hình 3. Các mount points của 2 volumes và một CD-ROM trong (A) Microsoft Windows và (B) UNIX system
Để giảm thiểu tác động của việc lỗi drive và để cải thiện tính hiệu quả, UNIX thường phân vùng mỗi đĩa thành một vài volumes. Một volume cho thư mục root (/) lưu thông tin cơ bản, một volume riêng rẽ có thể tồn tại cho các thư mục home của user (/home/), và các ứng dụng có thể được xác định trong volume của riêng chúng (/usr/). Tất cả các hệ thống là duy nhất và có thể có một volume và cơ chế mouting hoàn toàn khác. Một vài hệ thống sử dụng chỉ một volume lớn cho thư mục root và không phân đoạn (segment) hệ thống. Lý thuyết chung của lắp ghép Volume
Các hệ thống lớn hơn sử dụng các kĩ thuật lắp ghép volume để làm cho nhiều đĩa trông giống như một. Một động lực cho việc làm đó là để thêm tính dư thừa trong trường hợp một đĩa hư. Nếu dữ liệu được ghi vào nhiều hơn một đĩa, có tồn tại một bản sao backup nếu một đĩa hư. Một động lực khác đó là dễ dàng hơn khi thêm nhiều không gian lưu trữ. Việc mở rộng (volume spanning) thực hiện thông qua việc kết hợp tổng thể không gian lưu trữ của nhiều volumes vì vậy một volume lớn được tạo ra. Các đĩa bổ sung có thể được thêm vào volume lớn mà không tác động gì đến dữ liệu đã tồn tại.
Nào hãy cùng điểm nhanh một ví dụ. Hình 4 trình bày một ví dụ bao gồm 2 disk volumes với tổng cộng 3 partitions. Partition 1 được gán với một volume tên C: và một thiết bị phần cứng xử lý partition 2 và 3. Thiết bị phần cứng xuất ra một volume lớn, và được tổ chức thành 2 partitions. Chú ý rằng trong trường hợp này thiết bị phần cứng không cung cấp tính đáng tin cậy, chỉ là một volume lớn hơn.

Hình 4. Một hệ thống volume mà sáp nhập 2 partitions vào trong một volume và phân vùng nó
Đánh địa chỉ SectorChúng ta đã từng thảo luận về cách tìm địa chỉ sector. Phương thức phổ biến nhất đó là sử dụng địa chỉ LBA của nó, địa chỉ này là một con số bắt đầu từ 0 tại sector đầu tiên của đĩa. Địa chỉ này là địa chỉ vật lý của một sector.
Một volume là một tập hợp các sectors, và chúng ta cần gán một địa chỉ cho chúng. Một logical volume address là địa chỉ của một sector xét tương đối với bắt đầu của volume của nó. Chú ý rằng bởi vì một đĩa là một volume, địa chỉ vật lý là giống như địa chỉ logic của volume đối với disk volume. Các vị trí bắt đầu và kết thúc của các partitions được mô tả sử dụng các địa chỉ logic của volume (logical volume address).
Khi chúng ta bắt đầu nói về nội dung của một partition, có một lớp khác của các địa chỉ logic của volume. Các địa chỉ này là tương đối so với bắt đầu của một partition và không phải là bắt đầu của đĩa hay là parent volume. Chúng tôi sẽ phân biệt chúng thông qua việc đặt ở trước từ volume với từ "disk" hoặc "partition". Hình 5 cho ta thấy một ví dụ ở đó có 2 partitions và một không gian không được phân vùng (unpartitioned space) giữa chúng. Partition đầu tiên bắt đầu ở sector 0, vì vậy các địa chỉ logical partition volume là giống như các địa chỉ logical disk volume. Partition thứ 2 băt đầu ở sector vật lý 864 và các địa chỉ logical disk volume của các sectors này lớn hơn các địa chỉ logical partition volume của chúng.

Hình 5. Địa chỉ logical partition volume là tương đối so với bắt đầu của partition trong khi địa chỉ logical disk volume là tương đối so với bắt đầu của đĩa
Analysis Basics
Phân tích volume xảy ra thường xuyên, mặc dù nhiều nhà điều tra không thể nhận ra nó. Trong nhiều trường hợp, một investigator cần toàn bộ đĩa và import image vào trong các phần mềm phân tích của anh ấy để nhìn thấy nội dung của file system. Để nhận dạng nơi file system bắt đầu và kết thúc, các bảng partition phải được phân tích.
Một điều quan trọng nữa đó là phân tích partition layout của volume bởi vì không phải tất cả các sectors cần phải được gán vào một partition, và chúng có thể chứa dữ liệu từ một file system trước đó hoặc một mối nghi ngờ nếu đó cố gắng ẩn đi. Trong một vài trường hợp, hệ thống partition có thể bị lỗi hoặc bị xóa, và các công cụ được tự động hóa sẽ không làm việc.
Các kĩ thuật phân tích
Lý thuyết cơ bản của volume là đơn giản. Đối với các hệ thống phân vùng, chúng ta muốn xác định vị trí của các bảng partition và xử lý chúng để nhận dạng layout. Thông tin layout sau đó được cung cấp cho công cụ phân tích file system mà cần biết offset của một partition, hoặc nó có thể được in ra cho user do đó cô ta có thể xác định những dữ liệu gì nên được phân tích. Trong một vài trường hợp, dữ liệu trong một partition hoặc giữa các partitions cần được lấy ra từ parent volume. Để phân tích dữ liệu trong một partition, chúng ta cần xét xem kiểu dữ liệu của nó là gì. Nói chung, nó là một file system, chúng tôi sẽ trình bày trong những bài tiếp theo.
Để phân tích các thành phần lắp ghép (assembly components) của một volume system, chúng ta cần định vị và xử lý các cấu trúc dữ liệu mà mô tả những volumes được sáp nhập và cách chúng được sáp nhập. Có nhiều cách để các volumes có thể được sáp nhập.
Kiểm tra tính nhất quán
Khi phân tích các volume systems, có thể hữu ích khi kiểm tra mỗi partition liên quan thế nào tới các partitions khác. Điều này có thể phục vụ như là một cuộc kiểm tra sự tỉnh toán (sanity check) để xác định một nơi nào đó chứng cứ có thể được định vị bên cạnh việc nó xuất hiện trong mỗi partition. Hầu hết các partition systems không yêu cầu các entries được sắp xếp theo thứ tự, vì vậy bạn hay một công cụ phân tích nên sắp xếp chúng dựa trên vị trí bắt đầu và kết thúc trước khi bạn thực hiện các việc kiểm tra tính toàn vẹn.
Việc kiểm tra đầu tiên sẽ nhìn vào partition cuối cùng và so sánh vị trí kết thúc của nó với cuối cùng của parent volume. Lý tưởng nhất thì nó nên là sector cuối cùng của volume. Hình 6 cho ta thấy một tình huống mà ở đó partition sau cùng kết thúc trước cuối cùng của volume, và có các sectors có thể chứa các dữ liệu ẩn hay là bị xóa.

Hình 6. năm ví dụ về cách 2 partitions có thể được tổ chức tương quan lẫn nhau. Ba ví dụ đầu tiên là hợp lệ, 2 ví dụ cuối cùng là không hợp lệ.
Dạng tiếp theo của việc kiểm tra sanity là so sánh các sectors bắt đầu và kết thúc của các partitions liên tục, và có 4 tình huống xảy ra. Tình huống thứ nhất, hiển thị trong Hình 6b, là hợp lệ, và có các sectors nằm giữa 2 partitions mà không ở trong một partition. Các non-partitioned sectors có thể được sử dụng để ẩn dữ liệu và nên được phân tích. Tình huống thứ 2, ta có thể thấy trong hình 6c, là trường hợp mà hầu hết mọi system có, và partition thứ 2 bắt đầu ngay sau partition đầu tiên.
Tình huống thứ 3, có thể thấy trong Hình 6d, đây là tình huống không hợp lệ, partition thứ 2 bắt đầu khi mà partition 1 chưa kết thúc. Điều này tạo ra một sự chồng chéo, và trong nhiều trường hợp nó là một điềm báo rằng bảng partition bị lỗi. Để xác định partition nào là đúng, bạn cần phân tích dữ liệu bên trong mỗi partition. Partition thứ 2 nằm bên trong partition đầu tiên, các nội dung của mỗi partition cần được phân tích để xác định xem lỗi nằm ở đâu.
Trích xuất nội dung Partition
Một vài công cụ yêu cầu một partition image như là input, hoặc chúng ta có thể muốn trích xuất dữ liệu trong hay là ở giữa các partitions tới một file riểng lẻ. Phần này sẽ trình bày cách trích xuất dữ liệu, và các kĩ thuật trong phần này được áp dụng cho tất cả các partition systems. Trích xuất dữ liệu làm một quá trình đơn giản khi đã biết được layout. Chúng tôi sẽ trình bày cách thực hiện điều này thông qua công cụ dd .
Công cụ dd là một công cụ dựa trên command line và yêu cầu một vài thông số (arguments). Chúng ta sẽ cần những thông số sau để trích xuất nội dung partition:
- if: disk image để đọc
- of: file để ghi ra kết quả
- bs: kích thước của block cho mỗi lần đọc, 512 bytes là mặc định
- skip: số lượng blocks cần bỏ qua trước khi đọc, mỗi cho kích thước bs
- count: số lượng blocks để sao chép từ input tới output, mỗi đối với kích thước bs
Không có nhận xét nào:
Đăng nhận xét